今最も進化した音楽生成AIと言っても良いでしょう。
あまりに高度な、そしてアーティストの音楽スタイルのみならず、歌声までもが生成できるため、音楽のディープフェイクと称されるOpen AIの音楽生成ニューラルネットワーク “Jukebox”
https://openai.com/blog/jukebox/
4月30日の発表から2ヶ月少々経過しましたが、昨日(7月11日)にCANPLAYでもようやく講義として取り扱う事ができました。
その解説の中から一部を記事にして皆様にお伝えしたいと思います。
Jukebox概要
今回Jukeboxを発表したOpen AIは、イーロンマスクが設立時から支援を行っている事でも知られる非営利のAI(人工知能)研究機関です。
昨年2019年にMuseNetという、当時としてはもっとも高度な、音楽生成ニューラルネットワークを発表していました。
(MuseNet解説の過去記事はこちら)
https://canplay-music.com/2019/04/28/musenet/
そのMuseNetから約1年後の今回、新たな音楽生成ニューラルネットワークとして発表されたのがこのJukeboxです。
当初、Jukeboxは、MuseNetの機能向上版なのではないか?、、、と予想していたのですが、その予想を遥かに上回る、全く次元の違う高度な音楽生成ニューラルネットワークへと進化していました。
驚くべき進化です。
Jukeboxの特徴
Jukeboxの特徴です。
・MIDIデータではなくオーディオデータを学習および生成
・歌声まで生成
・詩も生成
・学習データは120万曲(うち約60万曲が英語の曲)
一番大きなインパクトはMIDIデータではなくオーディオデータそのものを学習&生成する事でしょう。
(MIDIとは電子楽器の共通規格で、異なる電子楽器やコンピュータ間で音符データのやりとりを行う事ができます)
先にお話ししたMuseNetも含め、これまでの音楽生成AIはすべてMIDIデータ(音符)を学習し、生成を行っていました。
もし音楽のオーディオデータそのものを学習し、生成が行えるのであれば、色々な音響情報を含めた、遥かに高度な事が実現できます。
しかしなぜ、これまでそれができなかったのか?
オーディオデータはMIDIデータに比べあまりに取り扱うデータ量が多いからです。
そのためオーディオデータを直接学習&生成する事は、不可能ではないが、まだ先だろう、それも段階的にであろう、と考えられていました。
ところが突然変異の様にいきなりそれを実現させたのがこのJukeboxです。
これに合わせ、これまでできなかった歌声の生成や詩の生成までをも、AI自身が行う事ができる様になりました。
驚きです。。。。
以前から波形領域での生成が行われる様になると、音楽への影響度は全く異なる大きなものになる、と解説し続けてきましたが、まさにその第一歩です。
AI音楽生成は、これまでとは次元もレベルも違う新たなフェーズに入ったと感じています。
Jukeboxサンプル曲
Jukeboxのサンプル曲を聞いてみましょう。
これまでAIでは生成が難しかった(MIDIデータでは表現が難しいため)ラップを2曲です。
音楽生成だけではなく、歌声(ラップ)や詩、演奏や音色までがAIによって生み出されたものです。
まずはNasスタイルのヒップホップです。
いかがでしょうか?
念のため断っておきますが、Nas本人のラップではありません。
AI、Jukeboxによる生成です。
次はEminemのLose Yourselfのリリック(詩)をKanye Westにラップさせたヒップホップを生成です。
これも再度繰り返しですが、Kanye本人ではありません。
ラップもAI生成です。
いかがでしょうか?
Jukeboxでこれらサンプル曲を視聴し、更に自分自身でも実装・生成を行った率直な感想は
「これは大丈夫なのか?、、、まずいのではないか?、、、」
でした。
もはや本人のいないところで本人らしい歌、詩、音楽が作られ、発表される、、、
そんな時代になるのか?、、、と、、、
タイトルに音楽のディープフェイクと書いた理由はここにあります。
Jukeboxの音楽生成は何がこれまでと違うのか?
これまでの音楽生成は、MIDIによる音符の数値データを基にしていました。
・音程
・タイミング(ジャストタイミングが中心)
・音色プログラム指定
・強弱(MIDIベロシティー単位)
などを数値データで学習し、生成します。
しかしこれには限界があります。
・音色(人の声や楽器の固有の特徴)の表現ができない
・音響特徴が表現できない
・ダイナミクスが表現でできない
など。
そもそも音楽作品として形にするには、歌や演奏、音響処理などを別途追加で行う必要があります。
そして実は、特に今の音楽というのは、この歌や演奏、音響の部分にこそ、その楽曲を特徴つけリスナーを惹き付ける重要な要素が詰まっています。
誰がどんな歌声で歌っているのか?、、、重要ですよね。
しかしこの重要な部分を、これまでのMIDIを基にした生成では、何も学習も生成も行えない、、、
この限界を超えれないのが、これまでの音楽生成でした。
もちろんAIによる音楽生成を研究する者は、私も含め、多くがこの事実に気がついてはいます。
しかし何故それが実現できなかったのか?
オーディオデータを基に生成しようとした場合、どの様な問題があるか?、、、
それはデータ数です。
例えば、
MIDIの場合標準的な4分の楽曲のデータ数は2000〜5000。
トラック数が多くても数万がせいぜいだと思います。
しかしオーディオデータの場合、CD音質(16ビット、44.1Khz)の4分の曲のデータ数)は1000万を超えます。
同じOpenAIで話題となったGPT-2 (文章生成のAI。フェイクニュースが作れてしまうと問題にされ当初公開が控えられた)でも1000データ程度が通常。
Open AI Five(ゲームAI。対戦型ゲームで世界チャンピオンに勝利)でさえ数万データです。

いかにオーディオを基にした音楽の学習・生成がデータが多いかお分かりいただけたと思います。
しかも音楽はデータの時間経過の整合性を維持しなければ音楽的になりません。
つまり計算や処理も、他のAI以上に複雑なものとなります。
これを解決するためにJukeboxでは、新たに画期的な3つのステップに分けられた処理を考案し行っています。
Jukeboxの音楽学習・生成方法
1・知覚的に無意味なオーディオデータを削減しオーディオを低次元空間に圧縮
2・この圧縮された空間(低次元)データで音楽を生成
3・生のオーディオデータにアップサンプリング(音質向上)
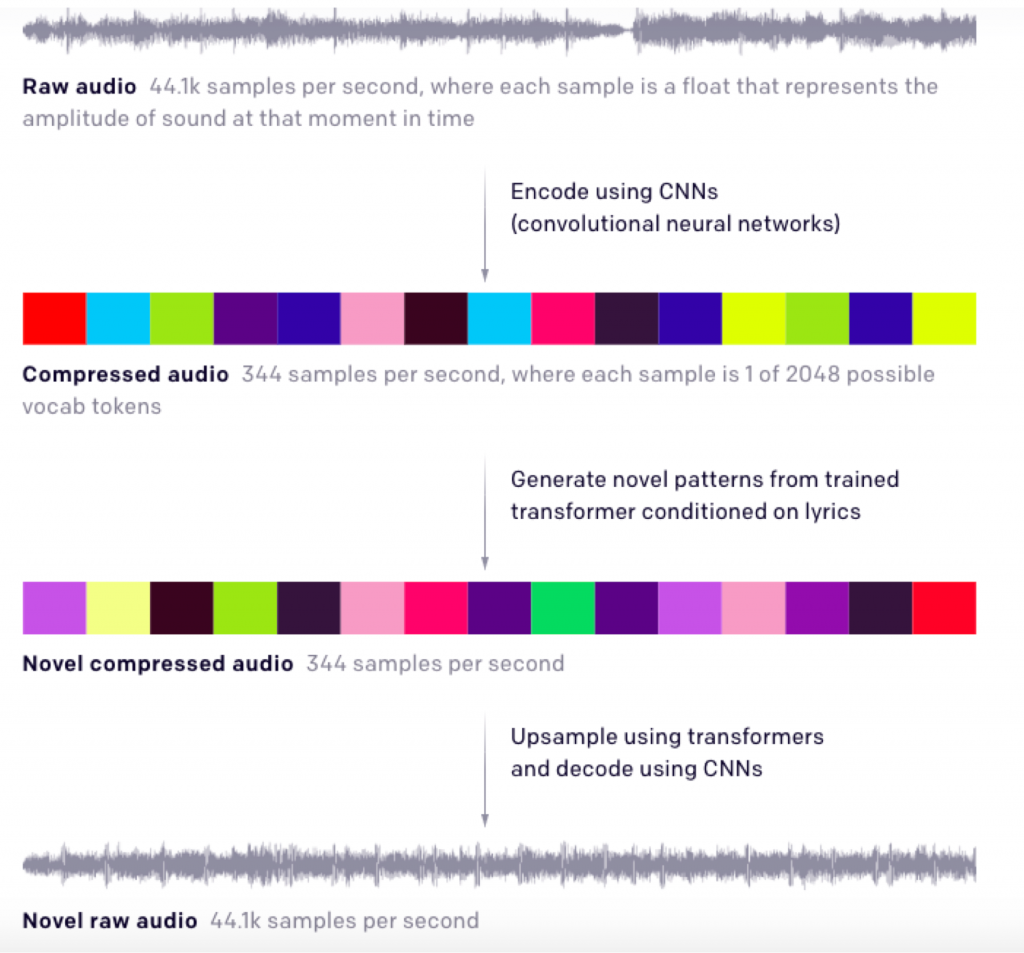
上図の1番目、元のオーディオ波形データです。
CD音質の44.1khzはつまり1秒間に44100のデータがあるという事です。
最初にステップ1として、これを1秒間に344データ 数まで削減します。
保持するデータは、音符情報や、歌声の特徴などです。
削減するのは音質に関わるデータです。
つまり音楽的な情報だけを残し音質を劣化させます。
この際2048の歌(詩)のデータから、該当するから1つが合わせてデータとして保持されます。
ステップ2では、この344データの低次元(低音質)の状態のままで音楽生成を行います。
最後のステップ3で、音質を元の44.1khz CDレベルにアップサンプリング(音質向上)させます。
以上の様な流れでオーディオデータを基にした音楽の学習・生成を実現しているのです。
Jukeboxのオートエンコーダ
データの削減にはエンコーダが使用されます。
Jukeboxで使用されるエンコーダはVQ-VAEと呼ばれる量子化ベースのVAE(Variational Auto Encoder)です。
さらに音楽用にVQ-VAE2と呼ばれる別のエンコーダからインスピレーションを得て、以下の様に段階的に音楽のデータ削減、音楽生成、アップサンプリングを行います。
下記は前述の3ステップのさらなる詳細をエンコーダの作業の流れで解説しています。
44.1khzの元のオーディオデータをエンコード
↓
8分の1にデータ削減(音質は悪くなるが音符データや歌声データを保持)
↓
32分の1にデータ削減(さらに音質は悪くなるが音符データや歌声データを保持)
↓
128分の1にデータ 削減(この時点で44100/128=データ 数344)
↓
データ 数344の低次元で音楽生成
↓
32倍にアップサンプリング(音質をあげる)
↓
8倍にアップサンプリング(音質をあげる)
↓
CD音質に戻す(デコード)
動画があるのでご確認ください。
データ削減ごとに音楽として知覚領域(メロディや歌声)を残しながら徐々に音質が悪くなっています。
これが削減されている部分です。
そして128倍圧縮(データを削減されている)の低次元領域で音楽生成を行い徐々にアップサンプリングで音質をCDレベルに戻しています。
Jukeboxのデータセット
Jukeboxの学習データ数は120万曲だそうです。
120万曲(うち60万は英語)をWebクロールで、対応するLyricWikiの歌詞とメタデータを組み合わせています。
メタデータには、アーティスト、アルバムのジャンル、曲の年、および各曲に関連付けられている一般的なムードやプレイリストキーワードが含まれます。
またデータ処理として、32ビット、44.1 kHzのオーディオを学習データとし、左右のチャンネルをランダムにダウンミックスしてモノラルオーディオを生成することで、データ拡張(データの水増し=同じデータを使用してデータ数を増やす手法)を実行しています。
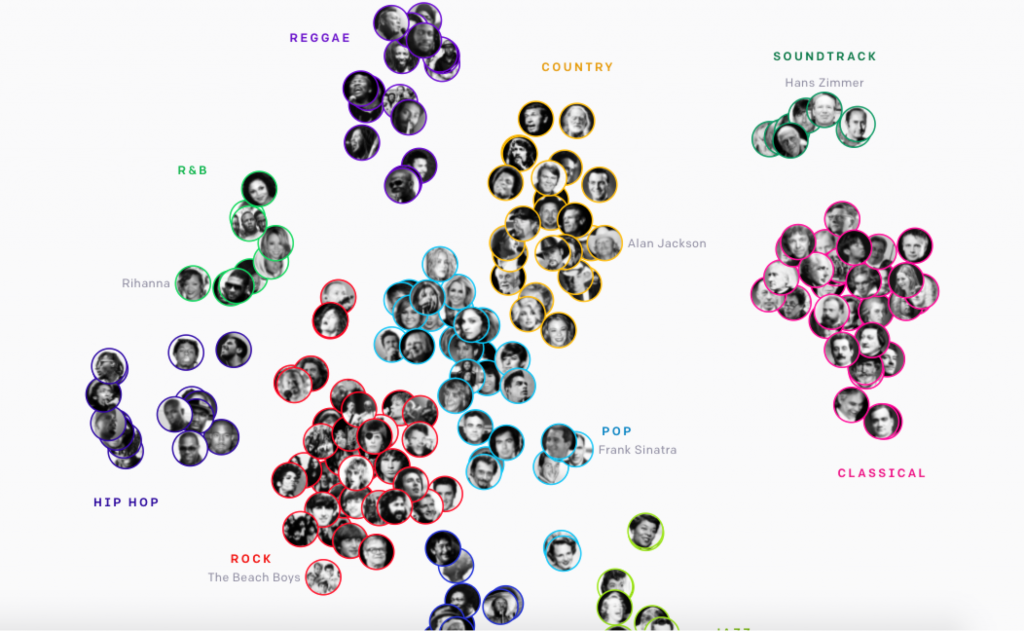
アーティストとジャンルの分類
Jukeboxでは教師なし学習のクラスタリングでアーティストとジャンルの分布を作成しています。
そしてこのクラスタリングで得たタグデータとして追加します。
これによりJukeboxでは他の音楽生成の手法にはない2つの大きなメリットを得る事に成功しています。
メリット1:学習の効率化 非対応ジャンルの学習を避ける事で不必要な処理を行わない
メリット2:生成時にアーティストスタイルやジャンル指定ができる
学習時には時間とニューラルネットワークの規模削減に貢献。
生成時にはJukeboxの大きな特徴である、アーティスト、ジャンルの指定が行える。
このメリットは実はクラスタリングの分類&タグ付けで同時に得られた物だったのは非常に興味深いです。
Lyric 歌詞の学習・生成
歌詞の学習と生成にも当初大きな問題があったそうです。
歌詞情報は単にテキスト情報でしか取得できず、テキスト(文章)としてのつながりを学習できても、音楽のどの位置に現れたのか、などの記録はできなかったからです。
このため、どの歌詞が、音楽のどの位置に該当する歌詞を出現させる、歌詞の時間経過の関係に整合性を持たせる、など、オーディオ情報と対応する歌詞を一致させるために
・歌詞の文字を音楽の継続時間に線形的に合わせる試み(成果を出すがヒップホップなど早い歌詞の曲に対応できない)
・Spleeter(Deezerが発表している音楽をパートごとに分割するプログラム)を使用し、ボーカルパートのみを抜き出し歌詞の正確な単語レベルの配置を取得
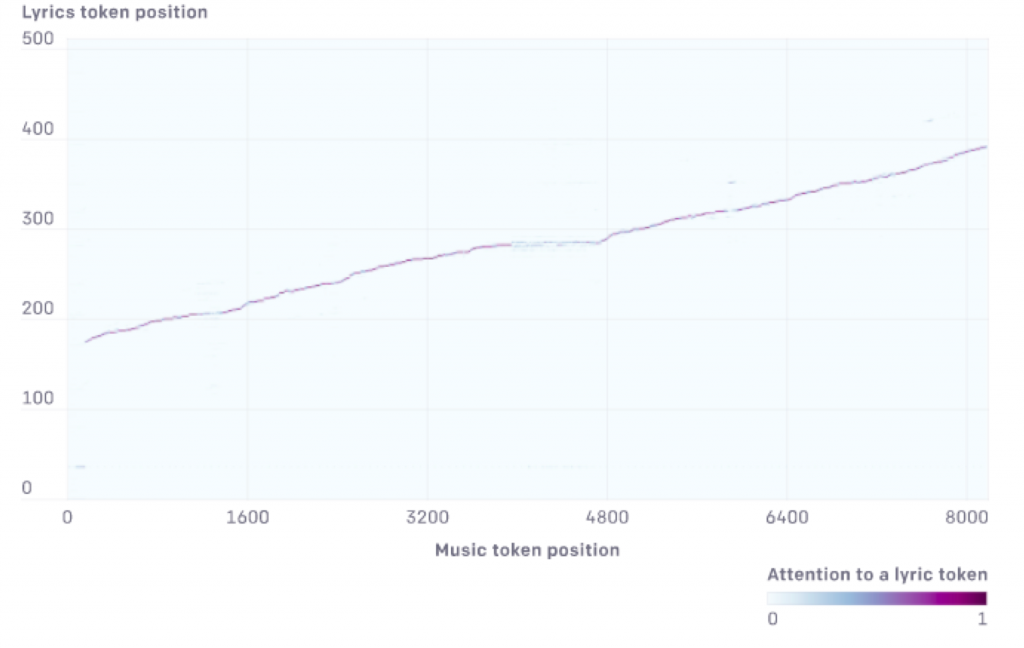
・歌詞生成専用のエンコーダーを追加して歌詞の表現を生成し、音楽デコーダーからのクエリを使用して歌詞エンコーダーのキーと値に対応するアテンションレイヤーを追加
などが行われたそうです。
これが非常に効果があった事は、生成曲からも確認する事ができます。
JukeboxとAI作曲の今後は?
先に述べた通り、あまりに高度すぎる生成は、著作権など権利関連で具体的な法整備が早急に必要では?、とこれまでになく強く感じさせました。
また使う側のモラルについて、これまでにはなく強く意識せざるを得ません。
残念ながら、今後Jukeboxの開発、アップデートは行われない様です。
当初からAI研究の一つであり、その目的をOpen AIとしては果たせたと考えているのかもしれません。
果たしてこれが最終版となるのでしょうか?